Big Tech spending in Brussels is insane…
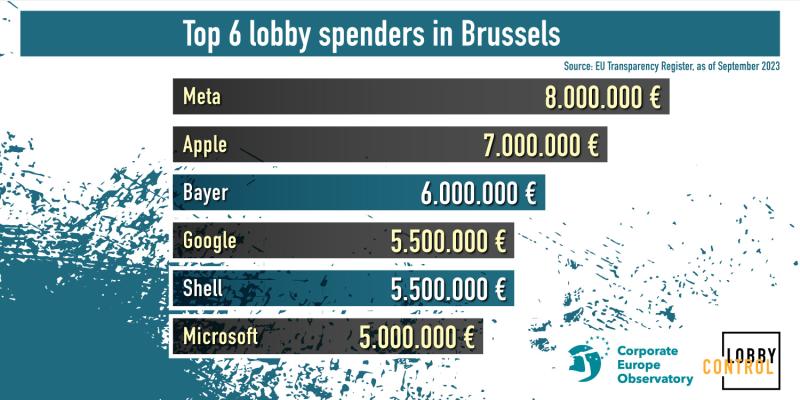
..and by insane, I mean insanely small compared to its impact. LobbyControl and Corporate Europe Observatory just published a great new report on Big Tech lobby spending. And…
..and by insane, I mean insanely small compared to its impact. LobbyControl and Corporate Europe Observatory just published a great new report on Big Tech lobby spending. And…

Recently, this graph made the round on Twitter. It shows how news headlines have been getting more emotionally intense over the years: They appear to be written specifically…

Note: This is cross-posted from my newsletter in an attempt to both to make it easier to read this via RSS feed and to have this in my…

There are two major threat models to consider when discussing algorithmic decision-making systems (ADM) — which I’ll get to in a moment. The other day, when I spoke to…

A topic that has been comic up a lot in conversation is a trend towards pushing regulation work to standards bodies. More concretely, for regulation in the context…

UN Habitat launched a new series of playbooks as part of its People Centered Smart Cities flagship program. I was happy to be a peer reviewer last year…

web3isgoinggreat.com is a pretty funny overview of the mishaps and shenanigans of the web3 / crypto scene and products. It shows just how much is going wrong in the…